Das KI-Betriebssystem entscheidet sich in der Datenbasis
Warum operative KI-Skalierung eine Frage der Daten- und Kontextarchitektur ist und was dateninspirierte Unternehmen heute anders machen
Jedes KI-Modell, das heute einen Wettbewerbsvorteil begründet, basiert auf einer Architektur, die morgen frei verfügbar sein wird. Der nachhaltige Vorsprung entsteht in der Daten- und Kontextbasis, die KI im operativen Maßstab zuverlässig versorgt. Diese Erkenntnis verändert, wie Führungskräfte ihr Data Management bewerten, priorisieren und entwickeln sollten.
Vermögenswerte als Daten begreifen
Was dateninspirierte Unternehmen verbindet, unabhängig von Größe, Branche oder Herkunft, ist eine gemeinsame Grundhaltung: Sie betrachten alle Vermögenswerte als Daten. Prozesslogik, Entscheidungshistorie, Domänenwissen, Qualitätsregeln: alles, was bisher in Köpfen, PDFs oder Legacy-Systemen gebunden war, wird systematisch in maschinenlesbare Formate übersetzt. Genau dort liegt der operative Kern der KI-Skalierung.
Zwei Ausgangsbedingungen, eine strategische Zielgröße
Startups und gewachsene Unternehmen starten von fundamental unterschiedlichen Positionen. Startups operieren mit überschaubaren Datenvolumina und KI-nativen Architekturen. Bei zwanzig Prozent Fehlerquote lässt sich der KI-generierte Output von hundert Ergebnissen pro Woche noch manuell absichern. Kontext entsteht beiläufig, weil wenige Köpfe das gesamte Prozess-, Entscheidungs- und Domänenwissen tragen. Implizites Wissen transformiert sich fast automatisch in explizite Daten.
Komplexe Unternehmen bewegen sich in einer anderen Größenordnung. Hunderttausende Dokumente, Terabytes an Daten, verteilt über Host-Systeme ohne Echtzeit-Zugriff. Bei fünf Prozent Fehlerquote entstehen tausende Eingriffe, die menschliche Prüfung erfordern. Jeder davon setzt Kontextwissen voraus, das auf tausende Köpfe verteilt ist und für KI strukturell nicht verfügbar steht.
Die strategische Zielgröße ist in beiden Fällen dieselbe: Die Grenzkosten jeder "Human in the Loop"-Aktion sinken, sobald operative Kontextqualität systematisch aufgebaut wird. Wer Daten- und Kontextqualität wertpriorisiert steuert, erschließt genau den Skalierungseffekt, den KI verspricht.
Drei Hebel für operative KI-Skalierung
Dateninspirierte Unternehmen, die KI erfolgreich skalieren, investieren gezielt in drei Bereiche.
Der erste ist Datendurchgängigkeit über Systemgrenzen hinweg. Legacy, Echtzeit und Cloud werden in einen kohärenten Datenfluss integriert, der KI-Systemen konsistente Eingaben liefert, unabhängig davon, wo Daten entstehen. Fragmentierung ist kein technisches Problem allein; sie ist ein strategischer Kostenfaktor, der KI-Ambitionen systematisch begrenzt.
Der zweite ist wertpriorisierte Daten- und Kontextqualität. Fehlerquoten werden dort gesenkt, wo sie den größten Kaskadeneffekt erzeugen. Das setzt voraus, dass Unternehmen wissen, welche Datenbereiche ihre KI-Anwendungsfälle tragen, und Qualitätsmaßnahmen entsprechend priorisieren. Qualität als flächendeckende Gleichverteilung ist eine Ressourcenfalle; Qualität als strategische Priorisierung ist ein Wettbewerbsvorteil.
Der dritte ist die Erschließung impliziten Wissens. Prozesslogik, Entscheidungsregeln und Kontextinformationen werden in maschinenlesbare Formate überführt, besonders dort, wo Routinen automatisiert werden sollen. Für KI-Agenten, die operative Entscheidungen treffen oder vorbereiten, ist dieser Kontext keine Ergänzung, sondern Voraussetzung.
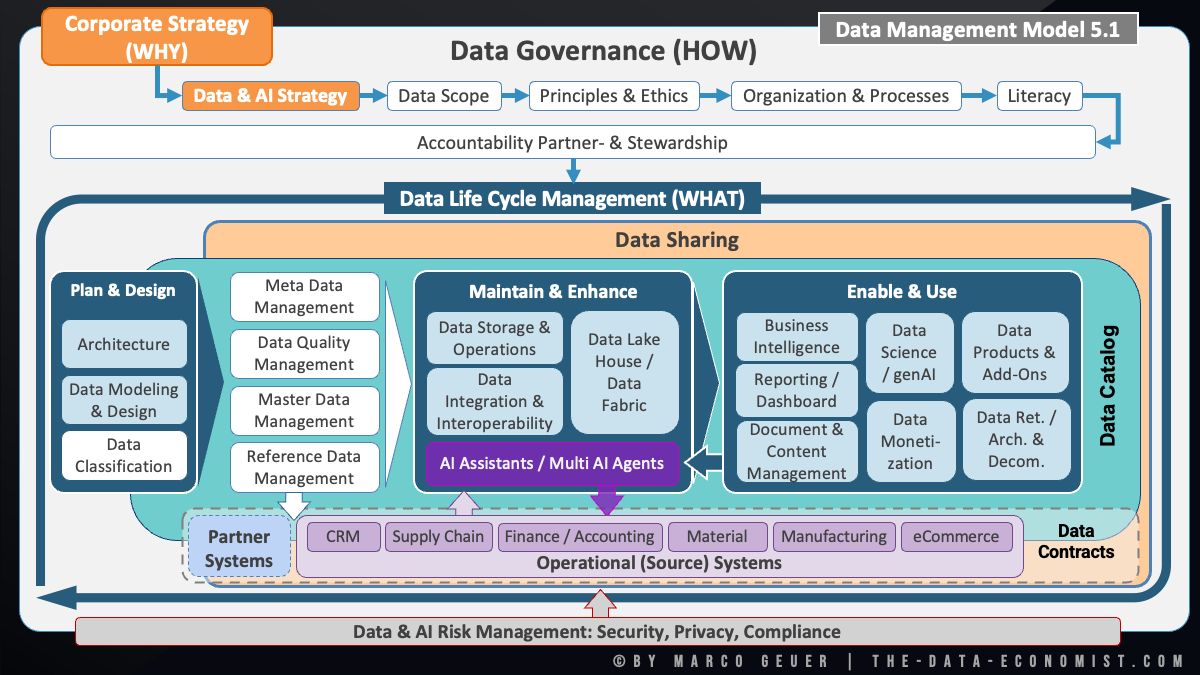
Das Data Management Model 5.1: Data Contracts als neue Kontextschicht
Das Data Management Model, das diese strategischen Ebenen strukturell abbildet, wurde in der aktuellen Version 5.1 um einen wesentlichen Baustein erweitert: Data Contracts. Sie verbinden die operativen Quellsysteme direkt mit dem Data Life Cycle und kodieren Governance-Informationen maschinenlesbar: Herkunft, Qualitätsstatus, semantische Definitionen, Zugriffsregeln, Aktualitätsgarantien.
In den meisten Unternehmen ist Governance heute ein dokumentarischer Prozess. Qualitätsregeln stehen in Wikis, Verantwortlichkeiten in Organigrammen, Nutzungsbedingungen in PDFs, die kein System automatisch prüft. KI-Agenten benötigen diese Informationen jedoch direkt am Datenprodukt, strukturiert und auswertbar. Wie das ganzheitliche Data Management Model 5.0 zeigt, sind Metadaten, Data Quality Management und Stewardship bereits strukturelle Bestandteile des Modells. Data Contracts erweitern diese Schicht um digitalisierte Governance: Sie übersetzen Regeln, Verantwortlichkeiten und Qualitätszusagen in ein Format, das KI-Systeme direkt auswerten können. Welche strategische Bedeutung das für die Skalierung von KI hat, beschreibt der Artikel Governance zu digitalisieren ist keine Option mehr ausführlich.
Startups gestalten Struktur, gewachsene Unternehmen entwickeln sie weiter
Startups bauen sauber, weil ihre Strukturen überschaubar und frei von gewachsener Komplexität sind. Saubere Strukturen unter diesen Bedingungen zu betreiben ist jedoch eine andere Disziplin als sie unter Wachstumsdruck stabil zu halten. Wer früh sauber baut, muss diese Strukturen aktiv verteidigen, sobald Datenvolumen, Systemzahl und Teamgröße wachsen. Die eigentliche Anforderung ist struktureller Natur: Architektur, die heute funktioniert, muss für den nächsten Komplexitätsgrad ausgelegt sein.
Für gewachsene Unternehmen führt der Weg zur KI-Skalierung durch die eigene Komplexität. Daten und Kontext sind über Jahrzehnte in Silos gewachsen, gebunden an Systemgenerationen und Prozessstrukturen. Der Hebel liegt darin, Fragmentierung schrittweise aufzulösen, die Daten- und Kontextbasis wertorientiert zu optimieren und neue Strukturen nach einer konvergenten Daten-, Kontext- und Prozessarchitektur aufzubauen.
Data Management erlebt seine strategische Renaissance, weil es über die operative Skalierbarkeit von KI entscheidet. Führungskräfte, die das früh erkennen, bauen heute das Fundament für den KI-Vorsprung von morgen.
Strategische Prioritäten für die Führungsebene
Wer den Skalierungseffekt von KI operativ erschließen will, sollte drei Fragen konkret beantworten: In welchem Bereich der Daten- und Kontextarchitektur liegt das größte Skalierungspotenzial für KI? Wo entstehen heute die höchsten Grenzkosten durch fehlenden operativen Kontext? Welche Governance-Informationen sind bereits vorhanden, aber noch nicht maschinenlesbar?
Die Antworten definieren den Startpunkt. Dateninspirierte Unternehmen investieren entlang der Wertschöpfungskette ihrer KI-Anwendungen. Die Architektur, die KI trägt, entsteht dort, wo Vermögenswerte konsequent in Daten übersetzt werden.
Das Data Management Model 5.1 visualisiert die vollständige Architektur: von der Corporate Strategy über Data Governance und Data Life Cycle Management bis zu den operativen Quellsystemen, nun erweitert um Data Contracts als maschinenlesbare Governance-Schicht.
Weitere interessante Artikel:
- Advisory | Impulse Talks | Trainings
- Der Frühindikator, den kein Dashboard zeigt
- Vergessen Sie den schnellen ROI: Die wirklichen KI-Gewinne stehen in keiner Bilanz
- Die stille Vollbremsung: Weshalb fehlende Datendurchgängigkeit die Wertschöpfung gefährdet
- Im Spannungsfeld von Wert und Verantwortung: Wie Unternehmen KI strategisch, regulatorisch und ethisch meistern
- Geändert am .
- Aufrufe: 988