Data Mesh Ökosysteme: Die Transformation zur Data Inspired Culture
Der Data Catalog 2.0 als wesentlicher Baustein der Self-Serve Data & Analytics Plattform und einer nachhaltigen Data-Mesh Infrastruktur
Das Konzept eines „Data Mesh Ökosystems“ als Zielbild im Rahmen einer Transformationen zu einer „Data Inspired Human Culture“ gewinnt zunehmend an Bedeutung in der modernen Datenverwaltung und -analyse. Es befürwortet einen dezentralen Ansatz in der Datenarchitektur und im organisatorischen Design gepaart mit einer Zentralen Self Serve Data & Analytics Plattform. Ein Data Mesh betont die dezentrale Datenverantwortungs- und Architekturstruktur, die auf spezifischen Domänen beruht, wobei domänenspezifische Daten zu wertorientierten Datenprodukten entwickelt und vermarktet werden, und somit als Produkt im Vordergrund stehen. Der Data Catalog spielt in diesem Ökosystem eine wesentliche Rolle, die eine effiziente Selbstbedienung und -Publizierung auf Datenplattformen ermöglicht.
Data Mesh Kernprinzipien
Der Data Mesh-Ansatz basiert auf vier Kernprinzipien, die zusammenarbeiten, um eine skalierbare, flexible und effiziente Dateninfrastruktur zu schaffen:
- Domain-Driven Design: Dieses Prinzip fokussiert auf die Bedeutung der Geschäftsdomänen als Haupttreiber der Datenarchitektur. Daten werden als Produkte behandelt, die von den Teams verwaltet werden, die die Fachkenntnisse für die jeweiligen Geschäftsdomänen besitzen. Dadurch wird eine enge Ausrichtung von Datenlösungen auf Geschäftsbedürfnisse erreicht.
- Selbstbedienungs-Dateninfrastruktur: Hierbei geht es darum, dass technische Teams Infrastrukturen schaffen, welche es Datenproduzenten und -konsumenten ermöglichen, Daten ohne externe Abhängigkeiten zu entdecken, zu verstehen und zu verwenden. Diese Infrastrukturen sind oft automatisiert und unterstützen eine effiziente Datenbearbeitung und -bereitstellung.
- Produktorientiertes Denken: Bei diesem Ansatz werden Daten als Produkte betrachtet, für die vollständige Verantwortung übernommen wird – von der Erstellung bis zur Bereitstellung und Wartung. Jedes Datenprodukt hat einen klaren Besitzer (das Daten-Produktteam), der für die Qualität, Sicherheit und Benutzerfreundlichkeit verantwortlich ist und dafür sorgt, dass diese Produkte wiederverwendet und mit anderen Produkten kombiniert werden können.
- Föderierte Daten-Governance: Dieses Prinzip zielt auf die Schaffung eines gemeinsamen Rahmens für Daten-Governance ab, der Konsistenz und Standardisierung über verschiedene Domänen hinweg gewährleistet, während gleichzeitig die Autonomie der einzelnen Domänen respektiert wird. Es geht darum, zentrale und dezentrale Governance-Modelle zu vereinen, um Datenqualität, Compliance und Datenverträge sicherzustellen, die es ermöglichen qualitativ hochwertige Datenprodukte, wie in einem Baukastenset, wiederzuverwenden und miteinander zu kombinieren.
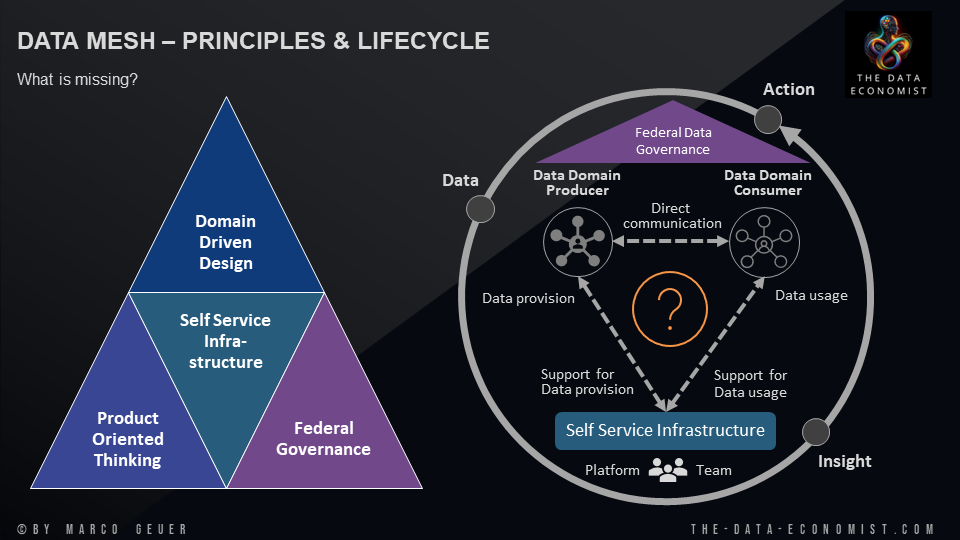
Herausforderungen bei der Transformation zum Data Mesh
Die Transformation zu einem Data Mesh bringt mehrere Herausforderungen mit sich, die sorgfältig angegangen werden müssen:
- Organisatorische Umstellung: Der Wechsel zu einer dezentralen Datenhoheit erfordert eine Veränderung in der Organisationsstruktur und -kultur.
- Komplexität des Designs: Das Design eines Data Mesh muss sorgfältig geplant werden, um eine Überkomplizierung zu vermeiden.
- Technische Integration: Die Integration verschiedener Datenquellen und -formate in einem dezentralisierten System kann technisch herausfordernd sein.
- Skalierbarkeit: Die Architektur muss skalierbar sein, um mit dem Wachstum der Daten und der Organisation mitzuhalten.
- Datenqualität und Governance: Die Sicherstellung von Datenqualität und Governance in einem dezentralisierten System stellt eine kontinuierliche Herausforderung dar.
Der Data Catalog als essenzieller Baustein einer Self Serve Data & Analytics Plattform
In der Welt der Datenanalyse und -verwaltung ist der Data Catalog ein entscheidendes Werkzeug, das Organisationen dabei unterstützt, ihre Datenlandschaft nicht nur zu verstehen, sondern auch aktiv zu gestalten und zu nutzen. Im Rahmen einer Data Mesh Self Serve Plattform fungiert der Data Catalog als zentrales Nervensystem, das eine Karte aller verfügbaren Datenprodukte und -dienste bereitstellt und somit die Selbstbedienungsfähigkeiten für Endbenutzer maßgeblich erweitert.
In einer solchen Architektur, die auf Selbstbedienung und produktorientiertem Denken basiert, ermöglicht der Data Catalog Nutzern, Datenprodukte zu entdecken, zu verstehen und zu nutzen, ohne sich auf zentrale Datenteams verlassen zu müssen. Dies fördert die Verantwortlichkeit und Partnerschaft zwischen Datenproduzenten und -konsumenten und sorgt dafür, dass Datennutzung kein Privileg, sondern ein allgemein zugänglicher Prozess ist.
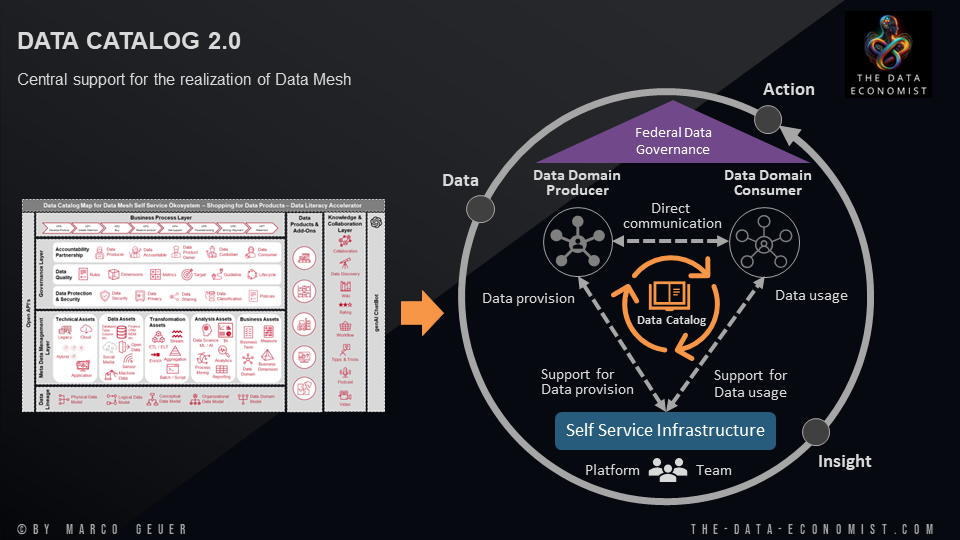
10 Kernpunkte zum Mehrwert eines Data Catalogs:
- Verbesserte Datenentdeckung: Ein Data Catalog ermöglicht es Benutzern, vorhandene Datenassets durchsuchbar zu machen und schnell zu identifizieren, was für ihre spezifischen Anforderungen verfügbar ist.
- Datenverständnis: Mit Metadatenmanagement und Kontextinformationen hilft der Data Catalog Nutzern, die Bedeutung, den Ursprung und die Qualität von Daten zu verstehen.
- Governance und Compliance: Er unterstützt Daten-Governance durch die Verwaltung von Richtlinien, Datenschutz und Sicherheitsvorschriften, was für die Einhaltung von Compliance-Anforderungen unerlässlich ist.
- Selbstbedienungsanalytik: Durch die Bereitstellung relevanter Informationen und Tools unterstützt der Data Catalog die Selbstbedienungsanalytik und fördert datengetriebene Entscheidungsfindung.
- Kollaboration fördern: Der Data Catalog dient als Plattform für die Zusammenarbeit, indem er Benutzerkommentare, Bewertungen und die Möglichkeit zum Teilen von Erkenntnissen bietet.
- Qualitätssicherung: Er bietet Einblicke in die Datenqualität und -metriken, sodass Benutzer die Zuverlässigkeit ihrer Analysen bewerten können.
- Datenzugriff und -nutzung: Der Data Catalog erleichtert den Zugriff auf Daten durch klare Richtlinien und Verfahren, wodurch die Nutzung von Daten vereinfacht wird.
- Effizientes Datenmanagement: Durch die Bereitstellung eines Überblicks über die vorhandenen technischen und geschäftlichen Assets hilft der Data Catalog, Redundanzen zu vermeiden und die Effizienz zu steigern.
- Unterstützung der Data Lineage: Er verfolgt die Datenherkunft und -bewegung durch das System, was für die Analyse und das Troubleshooting von Datenflüssen wesentlich ist.
- Innovationsförderung: Der Data Catalog kann als Inkubator für neue Ideen dienen, indem er einen Überblick über verfügbare Daten bietet und so Innovationen durch neue Nutzungsmöglichkeiten fördert.
Herausforderungen bei der Implementierung eines Data Catalogs
Die Implementierung eines Data Catalogs kann ebenfalls mit Herausforderungen verbunden sein:
- Datenintegration: Die Zusammenführung von Daten aus verschiedenen Quellen in einen zentralen Katalog kann komplex sein.
- Metadaten-Management: Die Erstellung und Pflege von Metadaten erfordert Ressourcen und eine kontinuierliche Anstrengung.
- Benutzerakzeptanz: Die Benutzer müssen den Wert des Data Catalogs erkennen und ihn in ihre Arbeitsabläufe integrieren.
- Datenschutz und Sicherheit: Es müssen strenge Sicherheitsmaßnahmen implementiert werden, um den Datenschutz zu gewährleisten.
- Wartung und Aktualisierung: Ein Data Catalog muss regelmäßig gewartet und aktualisiert werden, um seine Relevanz und Genauigkeit zu erhalten.
Fazit
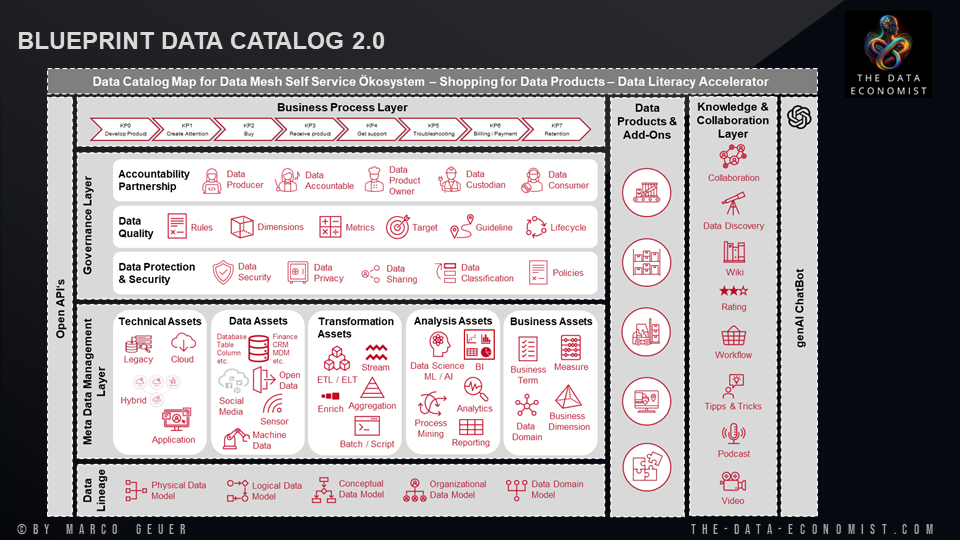
Die in den angefügten Bildern dargestellten Konzepte des Data Catalog Maps, des Data Mesh Lifecycles und der zentralen Unterstützung durch den Data Catalog verdeutlichen, wie essentiell ein gut strukturierter Data Catalog für das Funktionieren einer Data Mesh Architektur ist. Es ermöglicht eine agile, verantwortliche und sichere Datennutzung und fördert eine Kultur der Datendemokratisierung.
Data Catalog, Data Mesh, Data Fabric
- Geändert am .
- Aufrufe: 7549